Quick-Start Guide
Daidataset and Evaluation framework
Federated learning is proposed as a machine learning setting to enable distributed edge devices, such as mobile phones, to collaboratively learn a shared prediction model while keeping all the training data on device, which can not only take full advantage of data distributed across millions of nodes to train a good model but also protect data privacy. However, learning in scenario above poses new challenges. In fact, data across a massive number of unreliable devices is likely to be non-IID (identically and independently distributed), which may make the performance of models trained by federated learning unstable. In this paper, we introduce a framework designed for large-scale federated learning which consists of approaches to generating dataset and modular evaluation framework. Firstly, we construct a suite of open-source non-IID datasets by providing three respects including covariate shift, prior probability shift, and concept shift, which are grounded in real-world assumptions. In addition, we design several rigorous evaluation metrics including the number of network nodes, the size of datasets, the number of communication rounds and communication resources etc. Finally, we present an open-source benchmark for large-scale federated learning research.
Installation
Requirements
requirements.txt
matplotlib==3.1.1
pandas==0.25.0
pyparsing==2.4.1.1
pyrsistent==0.15.3
python-dateutil==2.8.0
torch==1.2.0
torchvision==0.4.0
Environment: python3.6
pip3 install -r requirements.txt
Usage
In our framework, we use the config.yaml as control module. After install the environment, we can download the origin classical dataset, edit the config module, partition the dataset once decided. Finally, we can use the result.
Module Usage
in conda
pip install galaxydataset
For Non-IID Dataset Generation
In this part, we use downloadData.py 、makeDataset.py and preprocess.py to generate non-IID datasets. More importantly, we provide a config file config.yaml for setting related parameters about non-IID datasets. We now work on MNIST and CIFAR10 datasets.
python3 downloadData.py

python3 makeDataset.py

python3 preprocess.py
The result is:

Setting config.yaml:
# dataset
dataset_mode: MNIST/ CIFAR10
# node num Number of node (default n=10) one node corresponding to one dataset,
node_num: 4
# small dataset config
isaverage_dataset_size: false # if average splits dataset
# numpy.random.randint(10000, 20000 , 20)
#dataset_size_list: [18268, 16718, 10724, 12262, 17094, 14846, 17888, 14273, 13869,
## 18087, 19631, 15390, 14346, 12743, 11246, 18375, 15813, 18280,
## 12300, 12190]
dataset_size_list: [1822, 1000, 1200, 1300]
# split mode
split_mode: 0 # dataset split: randomSplit(0), splitByLabels(1)
# each node - label kind , sum must <= 10
# numpy.random.randint(0, 11, 20)
node_label_num: [ 4, 3, 2, 10]
isadd_label: false
add_label_rate: 0.1
isadd_error: false
add_error_rate: 0.01
We will generate n custom datasets.
In downloadData.py:
We can download differents datasets.
In makeDataset.py:
In this part, we provide different methods for partitioning dataset.
- randomSplit: 1) no error dataset 2) add error dataset
- splitByLabel:
- just split dataset
- add other dataset, no error dataset
- add error dataset, no other dataset
- add both dataset
- redefineLabels
We will generate n custom datasets. On cifar10 files, every npy file consists of python’s List.
npy file: [[imgs, label], [imgs, label]...., [imgs, label]]
We can see the name of each npy file:
npy file name: split node index mode_dataset size_target label_the ratio of other label_the ratio of error dataset
In preprocess.py:
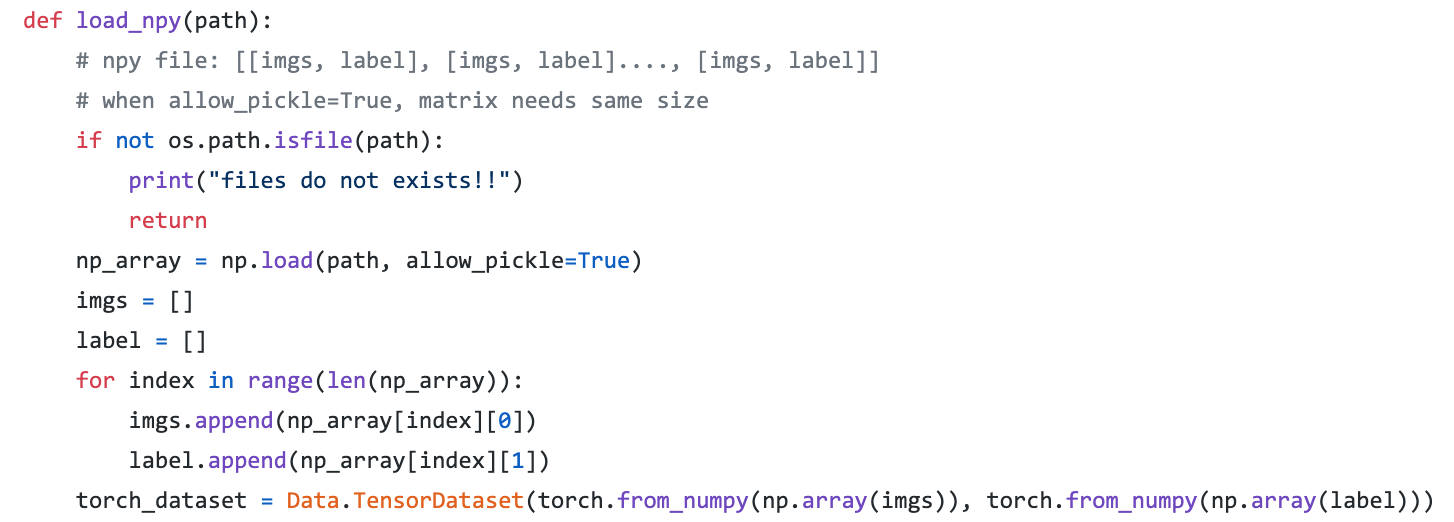
We will use readnpy method to read npy file
def readnpy(path):
# npy file: [[imgs, label], [imgs, label]...., [imgs, label]]
# when allow_pickle=True, matrix needs same size
np_array = np.load(path, allow_pickle=True)
imgs = []
label = []
for index in range(len(np_array)):
imgs.append(np_array[index][0])
label.append(np_array[index][1])
torch_dataset = Data.TensorDataset(torch.from_numpy(np.array(imgs)), torch.from_numpy(np.array(label)))
dataloader = Data.DataLoader(
torch_dataset,
batch_size=64,
shuffle=True
)
print(dataloader)
return dataloader
dataloader = readnpy("./XXXX/splitByLabelsWithNormalAndErrorDataset/SplitByLabels_2222_horseandMore_0.1_0.01.npy")
For NEI values
step1: Download datasets
python3 downloadData.py
step2: run NEI.py with datasets
python3 NEI.py
step3: get results about NEI values